
Wie im ersten Teil beschrieben werden Storage Policies (SPBM) an VMs bzw. Objekte angehängt. Dabei besteht so eine VM aus vSAN Perspektive eben aus verschiedenen Objekten:
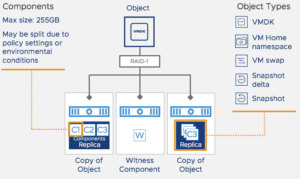 VM Home Namespace (VMX-Datei, Log-Files etc.)
VM Home Namespace (VMX-Datei, Log-Files etc.)- VMDK (bis zu einer Größe von 255GB, danach werden VMDK-Files in mehrere Objekte aufgeteilt)
- VM Swap
- Snapshot
- Snapshot Delta
Storage Policies können dabei an den VM Home Namespace und VMDKs angehängt werden – auch unabhängig voneinander. Snapshots werden automatisch mit der Policy versehen, die für die zugehörige VMDK gesetzt wurde.
Nachdem nun klar ist welche Objekte vSAN kennt, sollten wir uns dem Begriff “Komponente” widmen. Eine Komponente ist im vSAN Gebrauch die kleinste Eineheit. Ein Objekt setzt sich aus mehreren Komponenten zusammen. Beispielsweise wird eine VMDK mit einer Größe von 355GB in eine Komponente a 255GB und eine zweite Komponente a 100GB aufgeteilt. Wenn diese VMDK nun mit einer Fehlertoleranz von 1 gespiegelt wird, werden aus den 2 Komponenten 4 – jede Komponente wird nun synchron gespiegelt um die konfigurierte Fehlertoleranz einzuhalten.
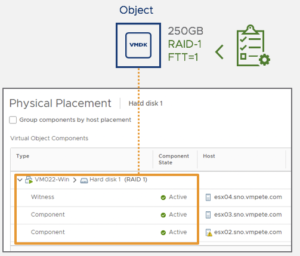 Wenn nun – wie in der oben dargestellten Situation – die Policy eine Fehlertoleranz von 1 vorsieht werden die Komponenten auf einen weiteren Host repliziert und dort synchron gespiegelt. Zusätzlich wird eine weitere Komponente für jedes Objekt angelegt – die Witness Komponente. Diese wird auf einen dritten Host abgelegt. So sind für jedes Objekt mindestens drei Komponenten vorhanden.
Wenn nun – wie in der oben dargestellten Situation – die Policy eine Fehlertoleranz von 1 vorsieht werden die Komponenten auf einen weiteren Host repliziert und dort synchron gespiegelt. Zusätzlich wird eine weitere Komponente für jedes Objekt angelegt – die Witness Komponente. Diese wird auf einen dritten Host abgelegt. So sind für jedes Objekt mindestens drei Komponenten vorhanden.
Wenn nun die beiden Hosts, auf denen die Datenkomponenten liegen, nicht mehr direkt miteinander kommunizieren können (Split Brain Szenario) kommt die Witness Komponente ins Spiel. Die Witness Komponente entscheidet dann welche der beiden Datenkomponenten “überlebt” und weiterhin schreiben darf. Die verbleibende Datenkomponente wird lesend geschaltet. Intern wird mit sogenannten “Votes” gearbeitet. Bei einer Fehlertoleranz von 1 und somit den beschriebenen 3 Komponenten bekommen die beiden Datenkomponenten jeweils ein Vote mit dem Wert 3, die Witness Komponente einen Vote mit dem Wert 2. Die Datenkomponente, die im Fehlerfall mit der Witness Komponente kommunizieren kann hat somit 5 Votes. Die verbleibende Datenkomponente nur 3 Votes – und würde sich damit unterordnen.
Fehlertoleranzen
Innerhalb der Storage Policies werden die Fehlertoleranzen definiert. Per Standard wird eine Fehlertoleranz von 1 angenommen. Doch was genau bedeutet das?
Fehlertoleranz meint, wie viele Komponenten ausfallen können, bis ein Objekt nicht mehr im aktiven Zugriff ist. Technisch wird dies als “Failures To Tolerate” (FTT) beschrieben. Ein FFT=1 beschreibt also, dass bei einem Objekt eine (Daten-)Komponente ausfallen kann ohne dass das Objekt offline geht. Bei FFT=2 besteht das Objekt aus 3 Datenkomponenten und es können somit 2 Komponenten ausfallen ohne dass das Objekt offline geht.
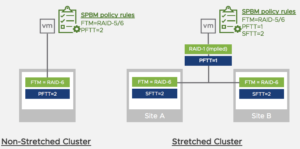 Bei einem vSAN Stretched Cluster existieren darüber hinaus noch weitere Fehlertoleranzmöglichkeiten. Mit der Primären Fehlertoleranz (Primary Failure To Tolerate = PFTT) wird definiert, ob ein Objekt in beiden Sites abgelegt werden soll. Somit wird ein Site-Ausfall abgefangen. Die Objekte sind in beiden RZ-Sites vorhanden.
Bei einem vSAN Stretched Cluster existieren darüber hinaus noch weitere Fehlertoleranzmöglichkeiten. Mit der Primären Fehlertoleranz (Primary Failure To Tolerate = PFTT) wird definiert, ob ein Objekt in beiden Sites abgelegt werden soll. Somit wird ein Site-Ausfall abgefangen. Die Objekte sind in beiden RZ-Sites vorhanden.
Die sekundäre Fehlertoleranz (Secondary Failures To Tolerate = SFTT) definiert dann, ob innerhalb der Sites zusätzlich noch weitere Komponenten erzeugt werden. Dabei wird ein Ausfall von einem (oder mehrerer; je nach Konfiguration) vSAN Host abgefangen.
Wenn im Beispiel der Abbildung eine PFTT=1 gewählt wird, dann wird das Objekt in beide Sites abgelegt. Es ist also ein RAID-1 über beide RZ-Sites konfiguriert. Durch die Definition von SFTT=2 werden innerhalb der Sites weitere Redundanzen geschaffen. In diesem Fall über die Fehlertoleranzmethode RAID5/6. Näheres dazu später.
Somit lässt sich auch bei einem vSAN Stretched Cluster granular festlegen welche Fehlerszenarien abgedeckt werden sollen.
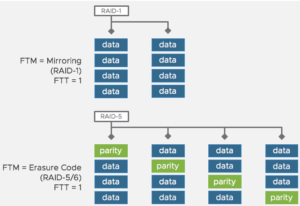 Neben den FTT-Einstellungen lässt sich auch die Fehlertoleranzmethode (Failure Tolerance Methode = FTM) definieren. Per Standard ist dies ein einfacher Spiegel, der einem RAID-1 entspricht. Optional lässt sich auch als FTM das sogenannte “Erasure Coding” aktivieren. In der Umsetzung ähnelt es dann einem RAID-5 bei FTT=1 bzw. einem RAID-6 bei FTT=2. Bei Erasure Coding werden die Komponenten plus Parity Informationen auf den Hosts im vSAN Cluster verteilt. Somit ergibt sich eine bessere Ausnutzung der Storagekapazität bei leicht niedrigerer Performance. Gleichzeitig werden bei FTT=1 und FTM=Erasure Coding mindestens 4 Hosts benötigt (besser: 5 Hosts auf Grund der Möglichkeit einer planmäßigen Wartung ohne verringerte Redundanzen).
Neben den FTT-Einstellungen lässt sich auch die Fehlertoleranzmethode (Failure Tolerance Methode = FTM) definieren. Per Standard ist dies ein einfacher Spiegel, der einem RAID-1 entspricht. Optional lässt sich auch als FTM das sogenannte “Erasure Coding” aktivieren. In der Umsetzung ähnelt es dann einem RAID-5 bei FTT=1 bzw. einem RAID-6 bei FTT=2. Bei Erasure Coding werden die Komponenten plus Parity Informationen auf den Hosts im vSAN Cluster verteilt. Somit ergibt sich eine bessere Ausnutzung der Storagekapazität bei leicht niedrigerer Performance. Gleichzeitig werden bei FTT=1 und FTM=Erasure Coding mindestens 4 Hosts benötigt (besser: 5 Hosts auf Grund der Möglichkeit einer planmäßigen Wartung ohne verringerte Redundanzen).
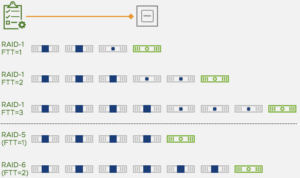
Die nebenstehende Abbildung zeigt die Anzahl der benötigten Hosts in Abhängigkeit der gewählten Fehlertoleranzen und der gewünschten Fehlertoleranzmethode.
 Bei einem vSAN Stretched Cluster und einem 2-Node-Cluster werden automatisch sogenannte Fault Domains gesetzt. Eine Fault Domain entspricht dabei einer Site und wird während der Konfiguration festgelegt. Bei einem vSAN Standard Cluster lassen sich jedoch diese Fault Domains händisch anlegen. Maximal werden 32 Fault Domains unterstützt.
Bei einem vSAN Stretched Cluster und einem 2-Node-Cluster werden automatisch sogenannte Fault Domains gesetzt. Eine Fault Domain entspricht dabei einer Site und wird während der Konfiguration festgelegt. Bei einem vSAN Standard Cluster lassen sich jedoch diese Fault Domains händisch anlegen. Maximal werden 32 Fault Domains unterstützt.
Mit Hilfe von Fault Domains lassen sich rackübergreifend Redundanzen abbilden. Wenn nun 12 vSAN Hosts in 4 Racks verbaut werden kann diese logische Abhängigkeit im vSAN nachgebildet werden. Wenn nun ein neues Objekt mit FTT=1 erstellt wird, dann werden die Komponenten in 3 verschiedenen Fault Domains platziert. Sollte also ein komplettes Rack ausfallen ist somit sichergestellt, dass keine Daten offline gehen.
Mit vSAN 6.7 Update 1 wird der Aufbau von Fault Domains weiter verfeinert. Innerhalb einer Fault Domain lassen sich sogenannte Nested Fault Domains erstellen. Damit ist es dann möglich ein Objekt in 2 Serverracks abzulegen (PFTT) sowie innerhalb eines Racks = einer Fault Domain zusätzlich zu spiegeln (SFTT).
Im nächsten Teil geht es dann um vSAN Data Services sowie die Witness Appliance.